Architecture in Practice: Building a Data Conversion Service
A few years back I led a fairly large round of service refactoring. A handful of those services ended up with designs I still feel good about, so I want to walk through one of them here. I’ll strip out the business specifics, but the internal architecture won’t lose anything important in the process.
The service I’m going to describe — let’s just call it the data conversion service — does roughly the following:
- Receive data from the legacy client protocol
- Receive data from the new client protocol
- Different data types, each with its own business processing logic (the “type” here is admittedly fuzzy — you can think of it as different protobuf message shapes)
- Different computation logic per type
- Different filtering and validation per type
- Forward the processed data downstream to multiple services
Functionally speaking: it exposes several inbound protocol endpoints to the world outside the cluster, and fans out to several downstream services inside the cluster. That kind of shape lines up almost perfectly with hexagonal architecture.
What’s hexagonal architecture? It’s described in Microservices Patterns. The short version: the outer ring is a collection of protocol adapters; the inner core is the business domain logic. Borrowing the textbook diagram:
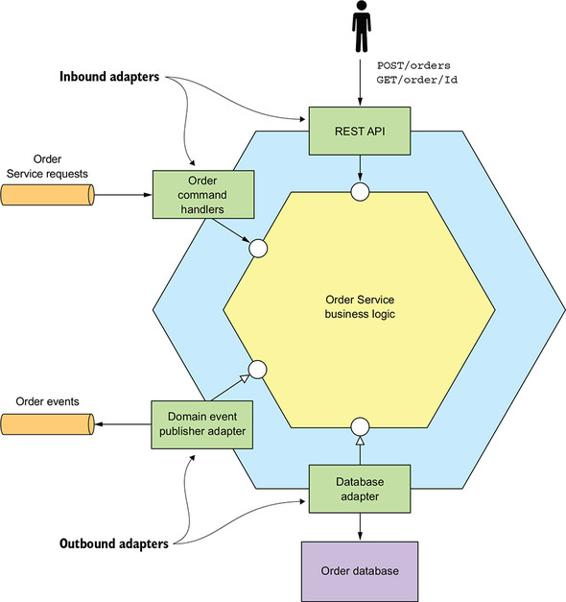
This is a different beast from classic MVC. MVC has a controller layer, a domain/business layer, and a storage/infrastructure layer, organized as a strict downward stack — by convention you don’t skip layers. That structure works fine for clean linear flows, but it starts to creak when a service has a lot of upstream and downstream relationships. Hexagonal architecture drops the strict layering. The MVC “domain layer” becomes the core, and around it sit a ring of protocol adapters:
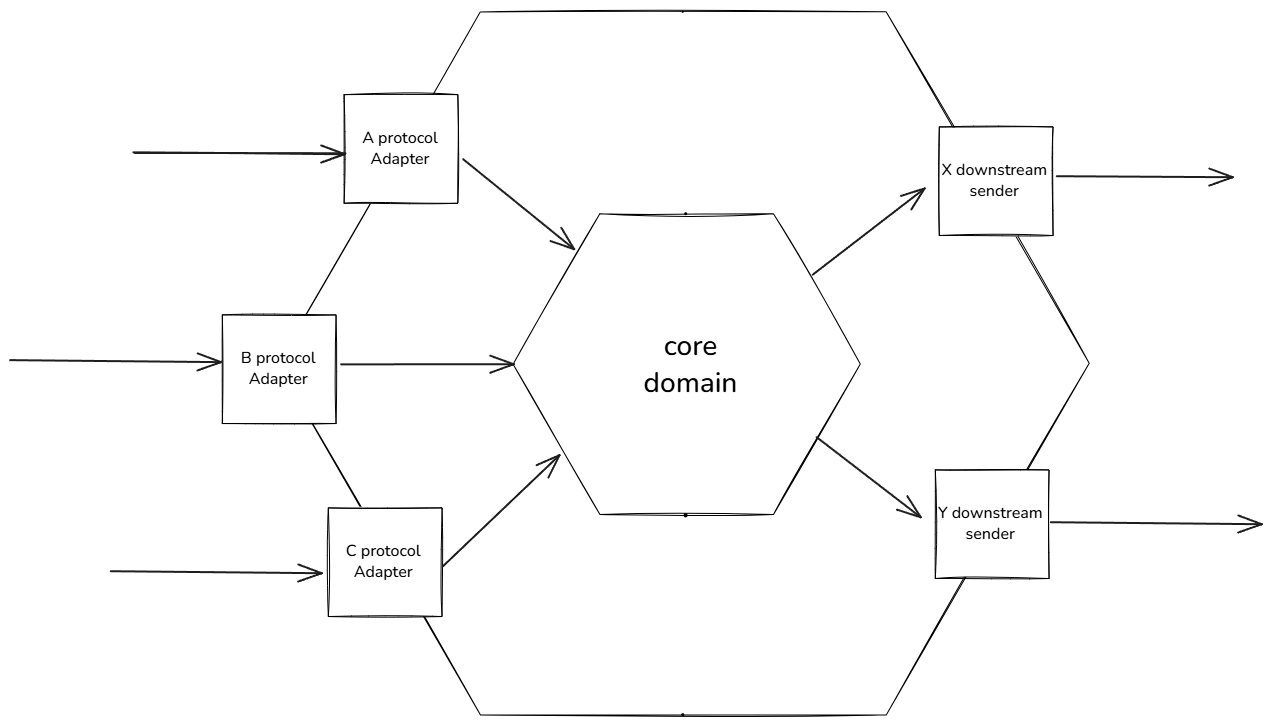
Roughly that shape. The service has no persistent state and no database interaction, which simplifies things considerably.
The inbound adapters speak HTTP to the outside world. Each adapter is free to expose whatever interface semantics make sense for that protocol, but inside the adapter, the protocol-specific data is normalized into a protocol-agnostic intermediate structure before being handed to the core domain.
The outbound adapters mirror this — they take in-memory data from the core domain and translate it into whatever wire format the corresponding downstream service expects.
The next design question: how should the adapters and the core domain be organized in code, and how should the threading look? When designing the internals of a service, I keep one twelve-character mantra in mind: 接口搭建框架,实现拓展细节 — use interfaces to build the skeleton; use implementations to fill in the detail. So the first thing to figure out is how to express this architecture through interfaces.
If you stare at the business logic, the whole thing collapses into a data processing pipeline. The processing path for any given piece of data is determined the moment it lands on an inbound adapter. That path consists of:
- Protocol parsing (deserializing the protobuf)
- Protocol adaptation (translating legacy-protocol data into the new protocol shape)
- Type-specific computation
- Type-specific business filtering
- Forwarding to downstream services
You can think of these as stages on an assembly line. The core of the service is just: receive a piece of data, walk it through the line. That shape is a textbook fit for the Chain of Responsibility pattern.
Chain of Responsibility: give multiple objects a chance to handle a request, decoupling sender from receiver. Hook those objects into a chain and pass the request along until one of them handles it.
For convenience, I’ll call each node on the chain a handler. Start with an interface:
public interface IHandler<T> {
bool handle(T data);
}Generic on T because — as mentioned — there are several data types, and each type’s processing logic specializes the template parameter to fit its own business rules.
To make life easier for the chain’s caller, layer in another pattern: Composite.
Composite: compose objects into tree structures to represent part-whole hierarchies, so that clients can treat individual objects and compositions of objects uniformly.
Implement a special handler that internally holds a list of handlers, and walks them in order inside its own handle method. From the caller’s perspective, there’s no chain — there’s just a handler:
public class IHandlerGroup implements IHandler<T> {
private List<IHandler<T>> handlers;
public bool handle(T data) {
for (handler : handlers) {
if (!handler.handle(data)) {
return false;
}
}
return true;
}
}With these two patterns combined, the adaptation, computation, filtering, and forwarding logic all wire together cleanly.
Still not perfect though. Multiple data types, each with its own computation, transformation, and filtering logic — the handlers multiply quickly. Composing them into the right chain in the right order is itself a non-trivial process. That logic should live in one place, where the complexity is encapsulated. Which lands us squarely on the Builder pattern.
Builder: separate the construction of a complex object from its representation, so that the same construction process can create different representations.
A few language and framework features come in handy here. We’ve got a pile of handlers, each handler is meaningful for a specific data type. So define a custom annotation that marks which data type each handler applies to. Then let Spring’s dependency injection collect every handler at startup, and let the builder use the annotation to dispatch each handler into the correct chain. Construction problem solved.
But not quite. All those handlers being hard-wired into the builder means: who decides their order? What if I want to disable one? Touching code for a tweak that simple is overkill. So lift the chain composition into a config file. Something like a YAML:
A-data-type:
- handler-1
- handler-2
- handler-3
- handler-4One question left: where do those names come from? Same trick — add another annotation that lets the implementer name the handler. Now it looks like:
public @interface HandlerAnnotation {
String name(); // name in config
DataType type(); // handler data type
}Any new handler that implements IHandler and adds the annotation gets picked up and slotted into the chain via the config file, without modifying a single line in any other file. That’s the Open/Closed Principle in practice. Clean.
So much for stitching the business logic together. On to the second question: what should the threading model look like?
The inbound adapters spin up their own I/O threads to listen for incoming requests — whether that’s pulling from a Kafka-style message queue, or accepting HTTP requests. Java’s typical approach is for the controller layer to run an I/O thread pool that blocks waiting on requests, usually backed by something like Netty’s NIO underneath. That pool’s threads are the framework’s; you generally don’t run business logic on them. You need a separate worker pool to do that work.
Which raises the obvious question: how do you map multiple chains-of-responsibility onto threads?
The first instinct is one worker pool per data type, each pool dedicated to one chain. But that ages badly. You end up with multiple pools and no good way to size each one. Threads above the CPU core count actively hurt rather than help. And you have no way to predict whether the data-type traffic mix will be balanced — making per-pool sizing a guessing game.
Better trick: collapse it back to a single pool, by leaning on the abstractions we already built. All processing logic is wrapped in a chain. The chain is itself wrapped in a Composite handler. From the controller’s perspective, it’s just an IHandler. Bundle that handler together with the data it should process into a single object — call it a Task. The task holds both the raw data and the processing pipeline:
public class Task<T> {
private final T data; // process data
private final IHandler<T> handler; // handler group
public handle() {
handler.handle(data);
}
}Note that T here has to accommodate the intermediate computation data, not just the raw inbound payload.
The controller submits a task to the pool. A worker thread pulls a task off the queue, calls task.handle(), and walks away. One pool, all data types, no per-type sizing problem.
Controller-side logic becomes embarrassingly simple:
- Receive data, do basic validation
- Look up the right handler by data type, wrap it into a Task, hand it to the pool
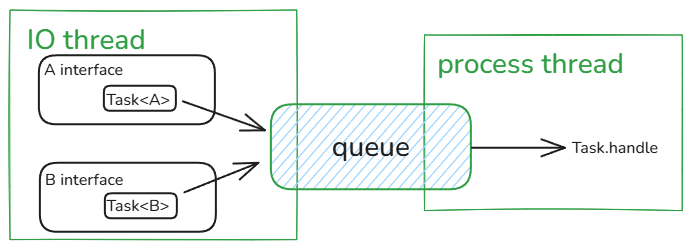
The threading picture is just as simple. Perfect.
That’s the internal architecture of a real production service. I’ve stripped the business specifics, but the design backbone is intact. After it shipped, four instances of this service absorbed all the traffic that twelve legacy services used to handle — call it a clean exit.
The original inspiration came from Envoy. Envoy is a high-performance L3/L4/L7 proxy, sitting at the data plane of the now-massively-popular service mesh world. It dynamically reshapes its protocol translation and forwarding pipelines via the xDS protocol, and the design ideas are essentially what we’ve walked through here. So if anything, this service comes from good stock.