When Queries Meet Distributed Systems
In modern enterprise architectures, breaking a system apart into microservices is a conversation you don’t really get to skip. Why microservices in the first place is a discussion for another day. Today I want to focus on one classic problem that emerges after the split: list queries.
The Problem with Distributed Queries
In a monolith, the core business data usually lives in a single relational database. Filters, pagination, joins — all of it can be handed off to the database via SQL. Someone else carries the weight; the application stays calm. Once you go distributed, though, the typical move is to give each service ownership of its own data, decoupling upstream and downstream services. The shape after splitting:
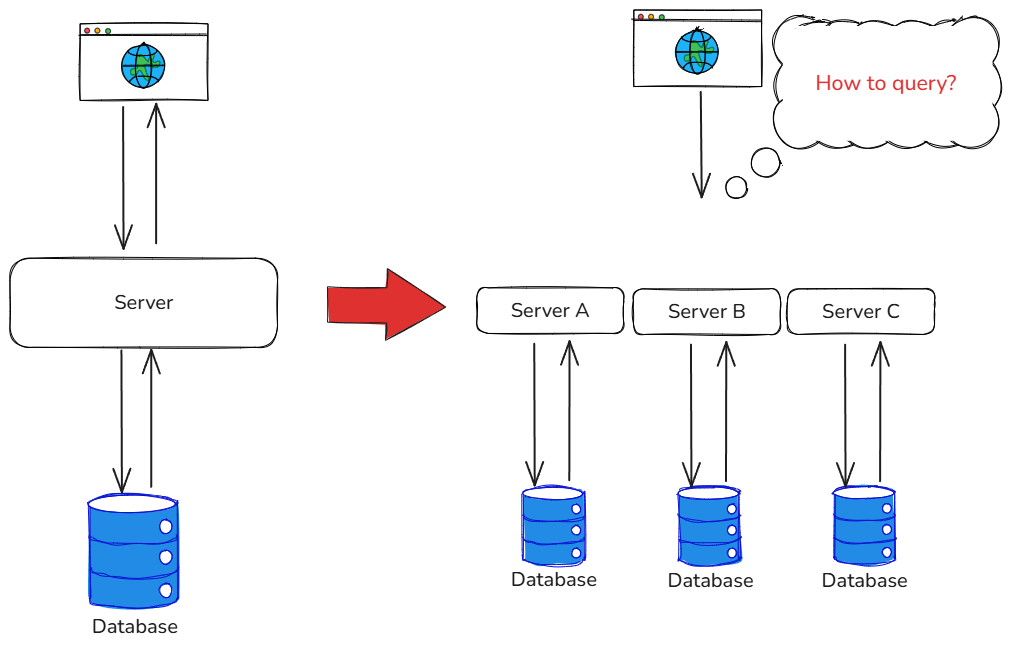
A query that used to be a single SQL JOIN is suddenly impossible inside a single database. Concrete example:
An e-commerce ops console wants to do user-profile analysis on a product. The team needs to be able to query users who bought certain products, and go the other direction — query the products bought by users matching a certain profile.
In the monolith, user info is in a
Usertable, product info is in aGoodtable, and purchase relationships are in aRecordtable. The query maps the filter onto the right columns ofUserandGood, joins them viaRecord, and returns everything in a single SQL.In a distributed setup, user info is owned by
User Serverand product info byGood Server. The two services only talk over APIs. Database-level joins are gone. That’s the distributed query problem.
Solution Space
The good news is the industry has been at this for years, and there are several relatively mature ways to deal with it. The bad news: compared to the simple, intuitive SQL of the monolith, every distributed query approach drags in significantly more implementation complexity.
The three patterns I want to walk through:
- API Composition. The most direct option. If a single service can’t answer the query, find a separate component that can — usually the API gateway sitting at the entry point.
- CQRS — Command Query Responsibility Segregation. SQL is naturally good at relational queries; the trick is to keep the data unified for query purposes while preserving each service’s data autonomy.
- Shared Database. Microservices doctrine says each service owns its own database. But if you let several services share one database for the sake of getting joins back, you keep the service split and recover the joins. Tempting on the surface.
But software has no silver bullets. Every solution is a new problem in disguise. The “no silver bullet” rule is part curse, part driving force — it’s the reason the field keeps moving forward. Architectural decisions are exercises in trade-offs, full stop. Each of these patterns has its strengths and its costs.
API Composition
The API gateway breaks a query into sub-queries, dispatches them to the responsible downstream services, then assembles the results in memory and returns them to the caller:
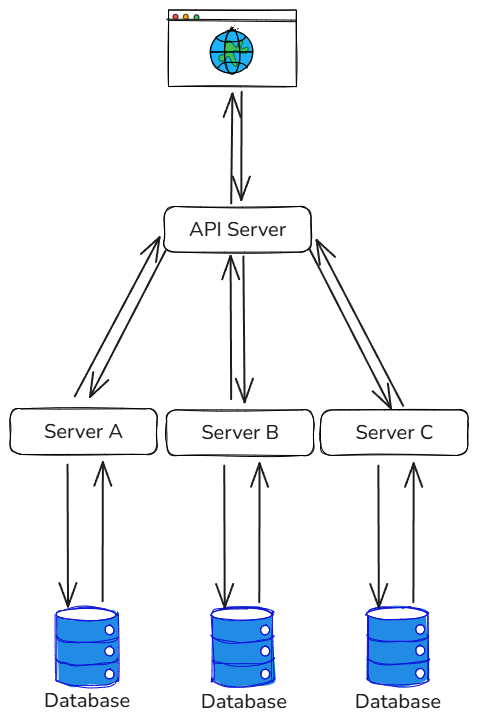
Because the data is sharded across separate databases, pagination logic moves out of the database and into the API server’s memory. Worse: when the filter spans data living in multiple services, the gateway has no way to know up front how much data each downstream service should return. Pull too much and you’re burning memory and bandwidth; pull too little and you can’t satisfy the page size.
There are two distinct shapes of API-composition queries to handle:
- Different entities. The data lives across multiple services and the gateway combines several entity types into one list. E.g., one request asks for both A products (in service A) and B products (in service B), and returns a single list containing both.
- Same entity, attributes split across services. The query targets one entity, but its attributes are scattered across services. E.g., some attributes of an A product live in service A and some in service B; the gateway has to merge attributes per ID before returning them.
These need different strategies.
Different entities
This case is relatively simple. Pull a fixed number of rows from each downstream service, sort the merged set by some agreed-on field, and paginate in memory. Two preconditions:
- A globally stable sort key. The data needs to be sortable globally and stably on some field.
- Cursor bookkeeping. Each downstream service’s pagination cursor has to be remembered, because the next round of results may pull more from one side than the other.
The two prevailing pagination styles in practice:
offset-limit—offsetis where to start,limitis how many to fetch.next-token/max-result—next-tokencarries the state for the next page,max-resultis the page size.
Important nuance: next-token is not required to be a value of any specific column. More commonly it’s an opaque, serialized state token whose payload may contain things like the last record’s sort-key value (timestamp, ID), the last record’s unique identifier, and the current pagination state (e.g., the set of IDs already seen, when filters get complex). Exposing it as a raw column value comes with security risks (information leakage) and functional limits (can’t handle composite sorts).
Even outside this distributed context, next-token/max-result is generally the better default over offset-limit. It’s faster, and the query latency stays consistent (deep pagination doesn’t get progressively slower). It’s especially useful here because the token can carry a composite cursor representing the per-service pagination state. In Go:
type unionIndex struct {
serverAIndex uint32
serverBIndex uint32
}The flow:
- The gateway receives the request and decrypts/decodes
next-token(encrypt the serialized form to avoid leaking implementation details). If the per-service cursors inside are empty, this is the first page. - Forward the query to each downstream service, asking for
max-resultrows. - Sort the returned rows by the agreed-on global sort key, then paginate in memory.
- Build the next composite
next-tokenfrom the slice that was returned. - Return both the page and the new
next-token.
Two points to watch:
- Backward pagination. The gateway only returns one
next-tokenat a time. To support paging backward, the client can cache historical tokens. - Filter changes.
next-tokenis tied to the current filter set. If the filter changes, pagination has to restart — you can’t reuse an old token to compute the new pagination state correctly.
Same entity, attributes split across services
This case is much harder. The “different entities” case is essentially a union across services — pulling max-result rows from each side guarantees enough data to fill a page. The “same entity” case is essentially an intersection — pulling max-result rows from each side does not guarantee a full page after the intersection collapses things.
Two paths through it:
- Materialize the full ID list. Fetch the entire set of matching IDs from each service in one shot, intersect them, sort and paginate that list in memory, then go back and fetch the remaining attributes by ID.
- Incremental top-up. Walk the cursor forward, pull pages from each service, intersect, and if the page isn’t full enough, advance the cursor and pull again — until the page is satisfied.
Walking through both:
Full ID list
The gateway forwards the filter (without pagination) to each service. Each service returns the full list of IDs matching the filter. The gateway intersects them, sorts and paginates the intersection in memory, and now has a finalized page of IDs. It then re-queries each service by ID to fill in the remaining attributes:
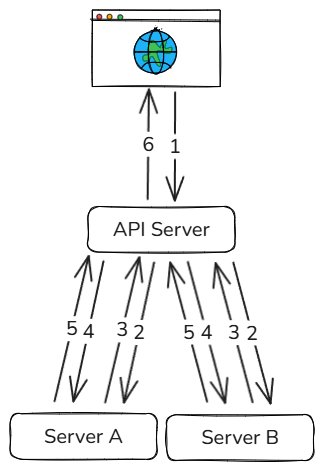
- Gateway receives the external query.
- Gateway forwards the filter (no pagination) to Server A and Server B.
- Server A and Server B each return the full set of matching IDs. Gateway intersects them in memory and paginates.
- Gateway re-queries each service by ID to get the rest of the attributes.
- Server A and Server B return the per-ID attributes. Gateway merges them by ID.
- Gateway returns the merged page.
To keep this from getting prohibitively expensive, cache the full ID list. As long as the filter doesn’t change between requests, subsequent pages can be served by paginating the cached list.
The first request, though, has to materialize the full ID list — potentially a lot of data to transfer. You also have to think about cache invalidation. Skip the cache and you can shrink the ID list as pagination advances (token-style), but at large data volumes the transfer cost is still rough.
Incremental top-up
In each round, pull a page from each service, intersect in memory. If the result is short of max-result rows, advance the cursors and pull again. Repeat until the page is full or some terminal condition fires. The flow is intuitive, but a few things need care:
- Termination conditions. Either you hit
max-result, or one of the services returns empty. To prevent runaway loops, set a hard cap on the number of rounds. - Next starting cursors. The trailing cursors of the rounds that didn’t fill the page.
- In-memory buffering. Rows pulled from each service have to be buffered, because the per-round IDs across services don’t line up exactly.
This approach behaves well on evenly distributed data — no need to ship a giant ID list around. But under heavy filter skew, you can end up shuttling a lot of useless data through the gateway.
CQRS
If the post-split databases can’t be joined, gather all the data needed for queries into a separate database. That database is read-only, query-purpose, decoupled from the original services, and doesn’t intrude on their write paths.
Shape:
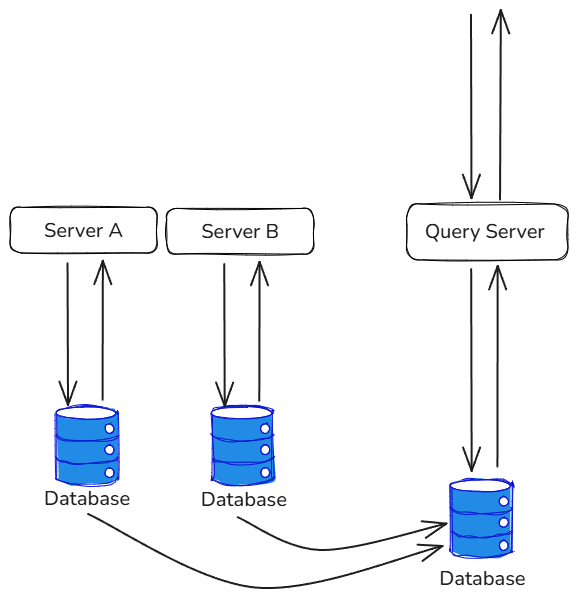
When Server A or Server B writes to its own DB, it also propagates the relevant fields into the read-only query database. The hard part is keeping the two in sync. Two key elements of the answer:
- Async message bus. Use Kafka or another message middleware to decouple the sync path. Failures in the sync pipeline can’t drag down the primary write path.
- CDC-driven sync (Outbox pattern). What triggers the sync? If the business service does it actively, it intrudes on the business code, and the service has to deal with consistency between two writes (DB write + outbound message). The microservices canon recommends the Outbox pattern: tail the database’s change-log (CDC pipeline) and let that drive sync downstream.
CQRS keeps the gateway free of huge query-aggregation logic — instead, complexity moves to the write side. The cost is query lag. CQRS therefore fits “read-lag-tolerant” scenarios (analytics, reports, ops consoles), and is a poor fit for “read-your-writes” scenarios (a user has to immediately see the order they just placed).
Shared Database
The shared database pattern is what it sounds like. The implementation isn’t worth elaborating. It looks the cheapest at first glance, but: there is no free lunch — its cost is hidden outside the code.
Software complexity has two faces: implementation cost and coordination cost between humans. The industry has, over time, evolved decent answers to most implementation problems. Coordination cost has gotten worse. The whole point of going distributed is to decouple responsibility and lower coordination overhead. Sharing a database directly violates that goal and quietly seeds long-term pain.
Why not share a database?
- Schema-change coupling. Database schemas are not stable. One service’s schema change can break others. Change cost goes up; blast radius goes up.
- Schemas are hard to retire. Without explicit versioning, the team owning the schema can only add fields — never remove them — so legacy fields have to be maintained on the write path forever.
- You can share data, not behavior. Joinable queries have to be expressible in raw columns; you can’t compute or aggregate on the fly while querying.
Summary
Pulling it all together:
| Dimension | API Composition | CQRS | Shared Database |
|---|---|---|---|
| Core idea | Decompose at the gateway, fan out, aggregate in memory. | Sync data from each service into a dedicated read-only query DB. | Logical service split with a physically shared database. |
| Query latency | High (especially deep pagination or multi-round aggregation) | Low (single-DB query), but with sync lag. | Low (monolith-like) |
| Consistency | Strong (queries hit the source of truth) | Eventual (query DB lags the source) | Strong |
| Implementation complexity | High (gateway query splitting, cursor management, aggregation, error handling) | Medium (business logic stays simple, but a reliable sync pipeline must be built and maintained) | Low (initial cost lowest; same as monolith) |
| Operational cost | Medium (no new infra, but the gateway can become a bottleneck and a single point) | High (requires maintaining MQ, CDC, query DB, etc.) | Very high in the long run (cost shows up in coordination and system evolution) |
| Scalability | Good (services scale independently; gateway can scale horizontally) | Good (read-write separation; the query DB scales independently) | Poor (DB is the bottleneck; can’t scale per service) |
| Fits when | Filters are flexible, consistency is critical, the number of services and data volume is modest. | Complex reporting and analytics; ops consoles; second-level lag is OK. | Quick prototypes; transitional stop-gaps. Strongly discouraged for long-term production. |
| Main strength | Most flexible; preserves service autonomy and data ownership. | Best query performance; converts a hard query problem into a comparatively simpler sync problem. | Fastest initial development; lowest barrier to entry. |
| Main weakness / risk | Deep-pagination performance is bad; memory and network costs are high; gateway logic gets gnarly. | Architectural complexity; data lag; potential data duplication. | Tight coupling kills service autonomy; schema changes blast outward; system evolution suffers. |
The essence of architecture is trade-off, not silver bullets.
For distributed queries: API Composition pays the complexity tax at query time, CQRS pays it at write time, and Shared Database pays it in the future.
- API Composition trades extreme implementation complexity at query time for clean service autonomy and strong consistency.
- CQRS trades query lag and architectural overhead for top-tier query performance and clean responsibility separation.
- Shared Database trades long-term tech debt and coordination overhead for short-term development convenience.
The choice isn’t to find the right answer. It’s to pick the most acceptable cost given your business’s tolerance for consistency, latency, and the shape of your team. Understanding those costs and managing them deliberately — that’s the actual core of building a robust distributed system.