A Long Look at Object-Oriented Programming
I’ve wanted to write something about object-oriented programming for a long time, and held off because the topic is both basic and enormous, and I wasn’t sure I could do it justice. Today, I’ll take a swing at it anyway.
OOP is one of those topics that’s been around forever but never quite gets stale. It’s been around because it’s old — half a century is a long time for any single approach to stay in active use in software. It stays fresh because its underlying ideas have spread far beyond their original context: from single-machine architecture to distributed microservices, you can still see the OOP fingerprint everywhere.
I first ran into OOP back in school. What is object-oriented programming? Encapsulation, inheritance, polymorphism. That answers what it is, but not why it exists. To get at the why, you have to go back to the historical context that gave rise to it.
In the 1960s, the industry hit what was eventually named the software crisis. Hardware was advancing fast, demand for software was exploding, and the procedural style of programming couldn’t keep up. There was no good way to organize code or contain complexity. R&D costs ballooned. Big projects with armies of engineers kept failing. That pressure produced “software engineering” as a discipline, and eventually OOP — and only after OOP did the crisis ease at all.
What’s Wrong with Procedural Programming?
There’s a small example at the start of Ruminations on C++ — a comparison between C and C++. Ostensibly it’s about the two languages, but it works just as well as a comparison between procedural and object-oriented thinking. The requirement is small: write a function that prints a log line to the terminal.
In C:
#include <stdio.h>
void log_print(char *s) {
printf("%s\n", s);
}Now suppose you want to add a switch — a flag that controls whether logs are printed. Two options:
- Add a parameter that controls whether the log fires. This pushes the decision out to every caller, drags more responsibility into the call site, and tightens the coupling between caller and callee.
- Use a global variable and check it inside
log_print. That introduces a global. Add another switch later and you’ve got another global. Then another.
Both options inflate complexity. Why?
In procedural programming, there’s no good place to keep a function’s state. A global variable becomes globally visible, with no real way to scope it. Take the logging example again: what if you want logs printed in some situations and silenced in others? The procedural reflex is to add the control variable to the parameter list; every place that calls log_print now has to thread that variable through. Or, more generally, you bundle it into a shared “context” struct and pass that through everywhere.
Sounds reasonable. It causes problems anyway:
- The function-to-function payload now mixes business data with control data. Control logic and business logic share a struct.
- The struct grows. (Look at Nginx’s many-layered indirections.) Cognitive load grows with it.
- As requirements iterate, more and more fields need threading through. Every new piece of business or control logic requires extending the struct. Reused fields and a fixed shape ossify the definition. Touch one thing and ripples spread.
Push a bit further. Now you want to write logs to a file. Two options again:
- Modify
log_printto write to a file. - Add a new file-writing log function and migrate callers.
Either way, adding a feature forces you to touch the old code.
The root cause of all this lives in the procedural model itself. Procedural decomposition splits software into two primitives: data and functions. Execution is “feed data into a series of functions, get an output.” Designs proceed top-down — the outermost function calls inner functions to compose the whole, building a pyramid-shaped call tree, with the leaf functions doing the smallest atomic work.
The procedural call pyramid:
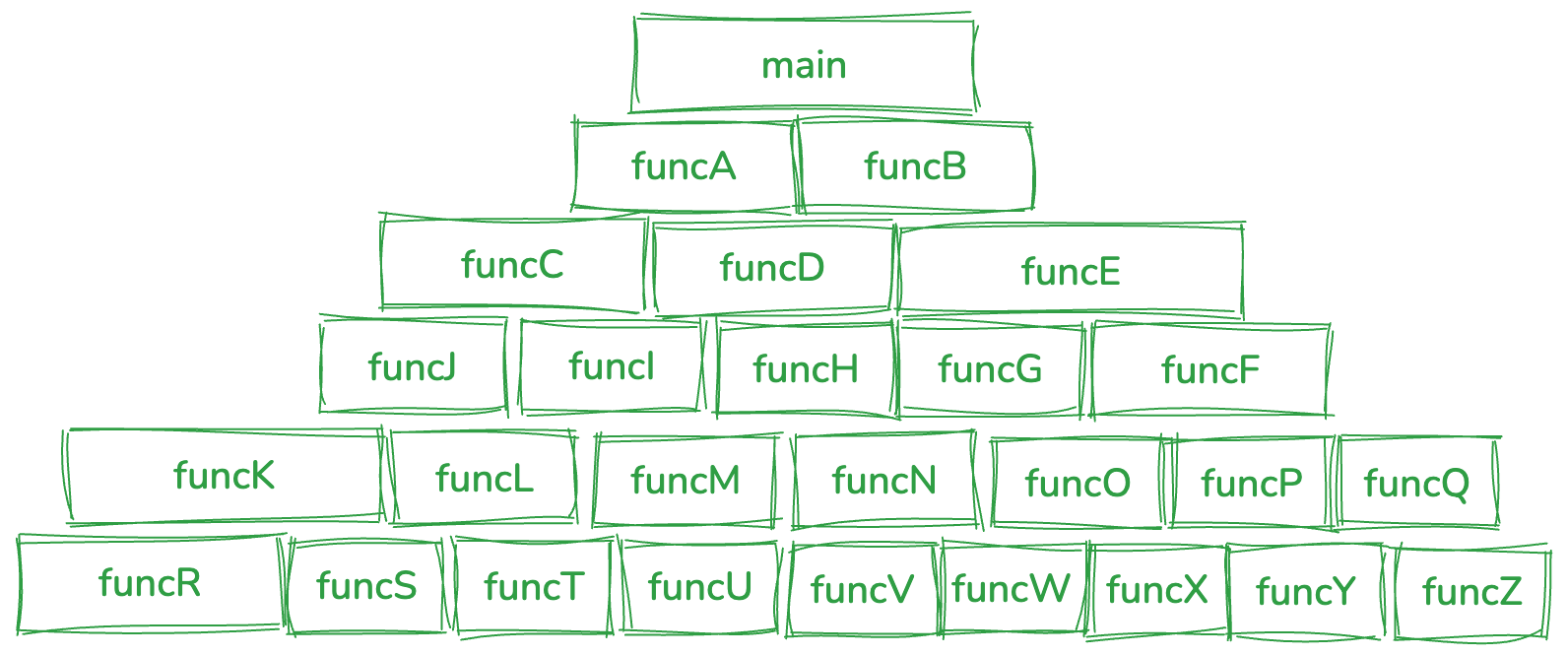
This shape leads to:
- Top-level functions can’t run until lower-level functions exist. You design top-down but build bottom-up. Changes near the bottom ripple upward.
- The pyramid resists extension. New business logic requires changing the existing structure, which means a wide blast radius and tests that have to grow with it.
- Call relationships are fixed at compile time. There’s no clean way to reshape them at runtime.
All of this together is what produced large-system complexity creep — projects sliding into the tar pit of The Mythical Man-Month, eventually surfacing as the software crisis.
How Does OOP Solve It?
OOP introduces the class. Strip it down and a class is a bundle of data and functions representing some real-world thing — internal state and behavior. In C++ and Java the compiler-provided this pointer references the instance; in Go and Python it’s even more direct, with the receiver passed explicitly into method definitions.
Every OOP textbook teaches the three pillars:
- Encapsulation — bundle data (attributes) and behavior (methods) inside a class. Hide internals; expose only the necessary interface.
- Inheritance — a subclass inherits attributes and methods from a parent class, and can extend or override them.
- Polymorphism — the same operation behaves differently across different objects, usually via method overriding or interface implementation.
Each pillar fixes a specific problem. Encapsulation addresses visibility — compile-time visibility checks make a class’s internals invisible to its users. Inheritance addresses code reuse and extensibility — you no longer reuse at function granularity; new functionality can be added in derived classes without modifying the base. Polymorphism addresses the rigidity of compile-time call structures — execution paths can be reshaped at runtime.
A note on how polymorphism is implemented: a class’s methods get stored in a virtual function table (vtable). The compiler builds a vtable per class at compile time. At runtime, the instance’s pointer is used to find its vtable, and the right method address is looked up there. It costs one extra pointer dereference compared to a direct function call, but it’s enough to let execution flow stop being a frozen if/else graph hard-coded at compile time.
These three pillars together unlock a deeper capability: abstraction — focus on what you care about, ignore what you don’t.
Suppose you’re building a racing-mechanics game and you need to model a runner. A person has many attributes — name, height, bank balance, etc. — but for our purposes only one matters: how they run. So:
class Runner {
public:
virtual void run() = 0;
};That’s enough. Tomorrow, the design changes to “the tortoise and the hare” — different animal, same race. Just inherit Runner and implement run() for each new species. The race-loop code at the top doesn’t need to know whether a person, a tortoise, or a rabbit is currently running. That’s what abstraction buys you. It inserts a contract layer between caller and implementation, hides implementation details from the caller, and lets you change the implementation without breaking the caller — that’s what we call decoupling.
Go’s duck typing pushes this further: if it walks like a duck and quacks like a duck, it’s a duck. What the duck is for — soup tonight, or release into a pond — is something animal-rights activists may care about, but software shouldn’t. Programs stop being procedural pyramids and become networks of interacting classes. You’re no longer modeling problems by carving up functions and defining data; you’re modeling them by abstracting concepts and simulating their interactions in code. Closer to how the world actually works.
So when does code count as “object-oriented”? Is writing C — which doesn’t natively support OOP — automatically procedural? Is writing Java — which is OOP through and through — automatically object-oriented?
Neither. OOP is a way of thinking about problems, not a property of the language. The essence is binding data to behavior and going through indirect (pointer/vtable) calls. Plenty of mature open-source C codebases (Nginx, the Linux kernel) use struct-with-function-pointer patterns extensively, which is OOP in spirit. And I’ve seen plenty of Java projects with sprawling globals, scattered direct accesses to data fields, and god-classes that touch every part of the business — that’s not really OOP either, regardless of the language.
So how do you actually do OOP well?

SOLID
Fortunately, smarter people than me have already done the homework. SOLID — coined by Uncle Bob in the early 2000s — is the canonical answer. SOLID is an acronym for five design principles:
- SRP — Single Responsibility Principle. A class or module should have one responsibility.
- OCP — Open/Closed Principle. Open for extension, closed for modification — extend by adding new files and classes, not by editing old ones.
- LSP — Liskov Substitution Principle. Subtypes must be substitutable for their base types.
- ISP — Interface Segregation Principle. Clients shouldn’t be forced to depend on interfaces they don’t use.
- DIP — Dependency Inversion Principle. High-level modules shouldn’t depend on low-level modules. Both should depend on abstractions. Abstractions shouldn’t depend on details; details should depend on abstractions.
If those still sound like incantations, let me walk through them.
Single Responsibility
The principle is intuitive: when designing a class, keep its purpose tight — one job. The hard part is scoping what counts as one job.
Take a Rectangle:
class Rectangle {
public:
void draw();
double area();
};draw renders the rectangle on screen. area computes its area. Is the design wrong?
If this class is used by a desktop application that draws shapes and does a bit of geometry, the design is fine. If it’s used by a backend system that will never draw anything, then draw doesn’t belong here at all.
There’s no absolute answer for scoping responsibility. Different problem spaces and different feature footprints justify different splits. Slice too thin and you end up with anemic classes everywhere, adding complexity. Don’t slice at all and you end up with bloated god-classes. My advice: in the early design phase, get the rough split right, and don’t over-tune. As requirements iterate and you maintain the code, both you and your team will develop a deeper understanding of the domain. Rather than agonizing over fine-grained splits up front, optimize for changeability — which is what the next several principles are about. That said, don’t go in completely heedless either; an obvious responsibility split early on is still essential. Everything in moderation. Without reading the situation, both leniency and strictness will cost you.
Open/Closed
OCP is the umbrella over the rest. The goal is to add new functionality without modifying existing code. Two clean wins:
- If new functionality doesn’t touch old code, the blast radius is contained, and tests are simple.
- It implies the architecture is pluggable. New engineers don’t have to spelunk through the old code to add features; they implement to a well-known contract and ship.
How do you actually obey OCP? Abstraction, again. Express intent through interfaces. Callers don’t see implementations. New functionality arrives by adding new derived types. For a reporting feature with multiple output formats:
class IReporter {
public:
virtual void generate(InputData) = 0;
};Different report types each implement this interface. Pair it with a static-registration factory:
class ReporterFactor {
private:
static std::map<std::string, IReporter*> reporter_map;
public:
static bool registe(std::string name, IReporter*);
static IReporter* getReporter(std::string name);
};Each new class registers itself with the factory; the application picks one dynamically (e.g., from config). Adding a new report format requires zero edits to existing code. The example is C++ specific because C++ has no reflection. In Java or Go, runtime scanning means new classes don’t even need to register themselves explicitly.
Liskov Substitution
A subclass must be able to fully replace its base class without breaking behavior. Sounds obvious, but in practice it’s frequently violated.
A common smell: people use inheritance purely as a code-reuse mechanism. My class looks like that one, so I’ll inherit from it. Then the behaviors don’t actually match, so callers end up sprinkling if/else based on the runtime type. That’s a textbook LSP violation.
The deeper point: classes derived from an abstract model should preserve the model’s meaning. Code reuse should sit on top of that semantic agreement, not the other way around. A Rectangle:
class Rectangle {
public:
virtual void SetLength(int length);
virtual int GetLength();
virtual void SetWeight(int weight);
virtual int GetWeight();
// ...
protected:
int length_;
int weight_;
};Two pairs of getters/setters, length and width. Now a Square. We learn in school that a square is a rectangle — a textbook IS-A relationship, perfect for inheritance:
class Square : public Rectangle {
public:
virtual void SetLength(int length);
virtual int GetLength();
virtual void SetWeight(int weight);
virtual int GetWeight();
// ...
};Looks fine. It’s not. The new Square carries both length_ and weight_, which is wasteful. More importantly, Square carries an implicit invariant — setting one of length/width has to set the other. The base class doesn’t have that invariant. That implicit rule is exactly the kind of mismatch that detonates in production at the worst time.
Interface Segregation
There’s a sibling principle — the Law of Demeter, sometimes called the Principle of Least Knowledge. ISP and LoD are saying related things. ISP: a class should depend only on the smallest set of interfaces it actually uses; it shouldn’t be forced to depend on methods it doesn’t need. I’ve seen plenty of components ship one giant union interface that catalogs every capability they offer — like a supermarket aisle, “take what you need.” That violates ISP.
Example: a user-operations interface:
class IUserOperations {
public:
virtual void viewProfile() = 0; // view info
virtual void changePassword() = 0; // change password
virtual void deleteUser() = 0; // delete user
};Different roles implement this. deleteUser is admin-only, so the regular-user implementation has to either return failure or throw. From the caller’s side, all methods are visible, even if the caller will never delete anyone. Worse — when the delete-user method changes, callers that don’t delete anyone are still affected. ISP says: split the fat interface into IAdminUserOperations and INormalUserOperations. Less interference, smaller blast radius.
Dependency Inversion
Earlier I described the procedural call pyramid: top-level logic depends on bottom-level implementations. DIP says don’t do that. High-level business logic should depend on abstractions, not on concrete implementations.
Why this matters becomes obvious the minute you try to write tests. Across the projects I’ve worked on, plenty couldn’t unit-test anything. They claimed to be agile but still ran a waterfall in disguise — heads-down build, then a long integration phase trying to wire the database, message broker, and other infrastructure together so that a request could be sent from the top and traced down through the call chain. DIP says: decouple from low-level details via interfaces. Linux did this decades ago — file operations are abstracted as a struct of function pointers:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};struct FILE console = {open, close, read, write, seek};The implementation behind those pointers can write to disk, memory, or the network. The caller doesn’t care. New file types can be added without touching the caller. That’s DIP, in plain form.
One More: Separating Control From Business
Outside SOLID there’s another principle worth dragging in.
All code falls into two buckets:
- Business logic — the actual feature. In e-commerce that’s orders and payments; in food delivery that’s order placement and dispatch.
- Control logic — supporting machinery for the business path: threading, retries, transport, scheduling, error propagation.
Business logic makes money. Control logic saves money. Good business design grows revenue. Good control design grows robustness, performance, and resource efficiency.
At the system-architecture level, the long-running trend has been to push control logic down — first into infrastructure, then into middleware, now into cloud-native primitives — so that application engineers can focus on business. The same principle applies to single components: don’t fuse the business core to the control layer. When you need to refactor the control layer, the business code shouldn’t move.
A Java threading example. Java offers a simple Thread wrapper — extend Thread and override run(), and you’ve got a thread. So you commonly see something like an order processor:
public class OrderProcessor extends Thread {
public void order_handle() {
// blocking receive + processing
}
public void run() {
order_handle();
}
}This binds threading concerns to business concerns. Want to change how threads talk to each other? You touch the business class. Want to add a new business flow — say, an order-cancellation processor? You spin up another CancelOrderProcessor extends Thread, redoing the threading wiring inside business code. Threading and business are conjoined; changing one drags in the other and constrains the architecture.
Cleaner: abstract the business processing as a contract:
public interface Bussiness {
void handle();
}Each business flow implements Bussiness. What gets handed across thread boundaries isn’t a business-specific input — it’s a Bussiness instance. The thread loop just calls handle(). The thread layer no longer knows anything about the business; the business layer no longer knows or cares which thread is executing it, whether the pool is shared or split. Full decoupling between control and business.
Of those five SOLID principles, SRP and ISP are about responsibility partitioning, OCP and DIP are about abstraction-driven decoupling, and LSP is a constraint on inheritance. With those tools laid out, the question “how do you actually use OOP well?” has more or less been answered.
You might still feel it’s a bit abstract. Principles are great, but how do you turn them into practice? That’s where design patterns come in.
Design Patterns
The literature on design patterns is enormous. I won’t go through them one by one. A high-level sketch instead.
There’s an old Chinese mnemonic for the 23 GoF design patterns that I’ve kept in my head for years. It rhymes — 单(Singleton) 抽(Abstract Factory) 工(Factory Method) 元(Prototype) 建(Builder) / 责(Chain of Responsibility) 令(Command) 策(Strategy) 访(Visitor) 迭(Iterator) / 中(Mediator) 观(Observer) 解(Interpreter),备(Memento) 模(Template Method) 态(State) / 适(Adapter) 装(Decorator) 乔(Bridge) 组(Composite) 享(Flyweight) 代(Proxy) 外(Facade). Each pattern fits a different design situation:
- Object creation — Singleton, Abstract Factory, Factory Method, Prototype, Builder.
- Behavior — Chain of Responsibility, Command, Strategy, Visitor, Iterator, Mediator, Observer, Interpreter, Memento, Template Method, State.
- Structure — Adapter, Decorator, Bridge, Composite, Flyweight, Proxy, Facade.
The mnemonic is the rough map — recite it five times every morning and your sleeves will start producing pattern names on demand.
Jokes aside: design patterns are best understood as proven OOP practices for recurring situations. Each pattern is an abstraction of a problem shape. A few examples:
- Factory — abstracts the creation of instances of a common interface, so callers don’t have to know the concrete type.
- Abstract Factory — abstraction over factories themselves. Many articles say it abstracts “product families,” which leaves people confused. Plainer version: an abstract factory creates factories, which create concrete instances.
- Builder — encapsulates a complex construction process. If creating an instance involves intricate logic, put that logic explicitly inside a builder.
- Chain of Responsibility — an abstraction for serialized strategy execution. When data needs to flow through a fixed sequence of policies, compose them as a chain.
- Strategy — abstracts an algorithm. When an algorithm has several implementations, lift the algorithm into an interface and swap implementations dynamically.
- Iterator — abstracts iteration so the caller can walk a collection without knowing the underlying structure.
- Observer — abstracts call relationships so callers don’t have to know callees; method invocation becomes event notification.
When you spot a similar shape in your own code, try a pattern first. Especially if you’re not yet at the level where you can reasonably invent a new pattern, you should be careful about saying “my approach is better.” The shape is so similar — what does your version actually buy you over the established one? That argument, of course, only works if you already know the patterns and their use cases. New developers often find pattern catalogs dry and abstract; reading them feels like chewing wax. That’s normal. Without enough code under your belt, design patterns are hard to internalize. The advice that’s worked for me: treat them like memorizing a poem — recite even if you don’t understand yet (the mnemonic helps), and keep an eye out for the shape in real code. Eventually it clicks.
We’ve covered a lot — why we needed OOP, how to use OOP well, what the best practices look like. Reading and writing aren’t the same thing, though. Many of these rules can’t be fully understood by reading about them; you have to learn what bad feels like before what good feels like makes sense.
Listen with your ears, think with your heart, and may the wisdom of code be with you.