很早就想写一篇关于面向对象编程的文章,一直担心才浅笔拙,没办法将这个基础而又宏大的话题讲清楚,今日斗胆为记。
面向对象是个老生常谈而又历久弥新的话题。历久是因为出现的年代早,在软件行业一个技术活跃半个世纪并不是常有的事情,弥新是因为其理论基础影响之深远,从单机的架构设计到分布式微服务都能看到它的影子。
最早接触到面向对象编程还是上学的时候,什么是面向对象编程?答曰: 封装、继承和多态。只回答了是什么,未能讲清为什么?而如果想要知道为什么,就需要追溯历史,看一看面向对象编程出现的时代背景。
上世纪六十年代,出现了软件危机: 计算机硬件的快速发展催生大量的软件需求,而过程化的编程方式无法有效的组织代码控制复杂度,项目的研发成本极速增长,大量付出海量人力的项目无可避免的走向失败结局,进而催生了软件工程的概念,一直到出现面向对象编程之后,软件危机才终于有所缓解。
过程式编程有什么问题?
我们从《C++沉思录》的开篇提到一个简单的C 和 C++对比的例子开始,其虽然是在说 C 和 C++ 的区别,但也可以看作是面向对象和面向过程编程方式的对比。需求非常简单:通过一个函数打印日志到终端。
C语言的实现:
#include <stdio.h>
void log_print(char *s) {
printf("%s\n", s);
}如果接下来我们要对日志输出做下控制,通过一个开关来决定是否打印日志。有两种思路:
给函数添加一个参数,控制是否输出日志,把控制逻辑交给调用方考虑。这会增加调用方的负担,职责划分上把开关功能定位在日志打印模块之外,也增加了调用双方的耦合关系。
设置一个全局变量,在函数内部通过判断全局变量的值来实现控制。这会引入一个全局变量,如果后期需要增加其他的控制开关,则需要引入更多的全局变量。
不论是哪种思路都会增加代码的复杂度。为什么会这样?
面向过程的编程方式中,没有合适的位置可以保存函数的状态,通过全局变量的方式会造成全局可见的变量,无法有效的进行访问控制。回到日志打印的例子,如果要实现某些条件下打印,某些条件下不打印怎么办呢?面向过程的思路是将这个控制变量添加到参数中,这样每个调用日志打印的地方都要维护一个局部的参数,或者更通用一点,将这个控制变量添加到一个类似上下文概念的数据结构中,在处理过程中所有调用到日志打印的地方都提取这个变量作为参数传入。
听起来还不错,但这会出现几个问题:
-
函数间传递的参数中除了业务数据,还需要包含日志打印控制数据,控制逻辑和业务逻辑耦合在一个结构体中。
-
庞大的数据结构定义增加复杂度的同时会极大得增加认知负担(Nginx中的多层指针)。
-
随着需求迭代,需要透传得参数会越来越多,每添加一个特定的逻辑(业务逻辑或者控制逻辑),都需要在这个数据结构中添加相应的变量控制,复用变量和固定的结构都会导致定义越来越固化,修改起来牵一发而动全身。
我们再进一步,现在要添加一个功能,将日志输出到文件中,该怎么办呢?两种方案:
-
修改log_print函数的实现, 将内容输出到文件中。
-
添加一个新的写入文件的日志函数,调用方做改动。
不论哪种方案,新的功能拓展必然会修改到旧的逻辑代码。
上述问题的根本原因在面向过程编程对问题的建模方式上。面向过程将软件拆分为两个基础单元:数据和函数。软件执行的过程就是将数据输入到一系列的函数然后得到对应的输出。在软件设计阶段常常是由顶向下的方式进行结构设计,最顶层的函数依次调用下层的函数来实现整体功能,函数调用栈组成一个类似金字塔的结构,将问题拆解到不同层级的函数中,最底层的函数实现最细粒度的功能。
函数调用金子塔:
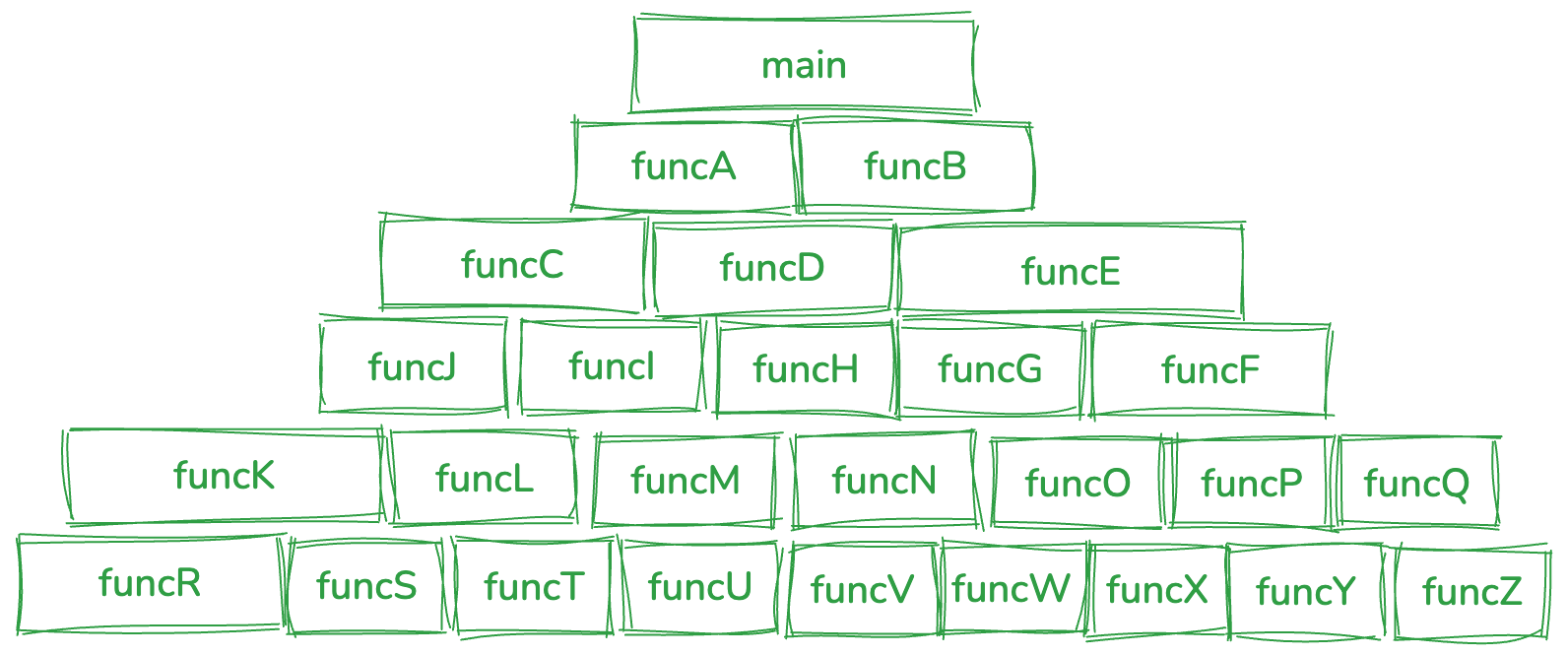
这样的结构导致:
上层的函数要等到下层函数的功能完善才能执行,自顶向下设计,自下向上实现的过程,下层的函数变动会影响到上层函数。
函数组成的金字塔调用结构缺乏拓展性,引入新的业务逻辑需要修改旧的结构来支持,无法控制修改范围,也无法有效得隔离变化,造成测试范围扩大。
固定的函数调用关系,在编译期即确定,缺乏动态调整函数调用关系的能力。
以上的种种问题综合在一起,造成了大型软件系统复杂度膨胀,陷入人月神话的焦油坑中无法自拔,进而出现了软件危机。
面向对象怎么解决?
面向对象引入了类的概念,从本质上讲类就是将数据和函数绑定在一起,可以用过自定义类来表示一种具体的事物,这个事物有自己的内部状态(数据)和行为(函数)。在C++和Java这类语言中,通过编译器内建的this指针来指向类的实例以访问到成员变量。在Golang,Python这类语言中则更直观一些,需要在成员函数定义的时候显式得传入指向类实例的参数。
我们在任何面向对象编程的教科书中都会看到三大特性:
-
封装:将数据(属性)和操作数据的方法(行为)绑定在一个类中,隐藏内部实现细节,仅对外暴露必要的接口。
-
继承:子类可以继承父类的属性和方法,并可以扩展或重写这些功能。
-
多态:同一操作在不同对象中表现出不同的行为,通常通过方法重写(Override)或接口实现达成。
三种特性分别解决了什么问题?封装解决了可见性问题,通过访问属性在编译阶段进行可见性检测,使类的内部实现对使用方完全透明。继承解决了类间的代码复用和拓展性问题,我们不用再以函数为粒度复用代码,更可贵的是新功能可以在继承的派生类中实现,而无需修改旧的类代码。多态解决了运行期间无法调整调用结构的问题。
简单讲一下多态的实现原理: 将类的行为(函数)存放到一个虚函数表中,编译期间构建虚每个类的虚函数表,运行期间通过实例指针访问不同的虚函数表,从而实现在运行期动态调整软件执行流程,比函数调用多了一次指针寻址过程,使代码的执行逻辑不再是固定编码的 if else 流程。
通过上述三种特性的组合,是我们得到了一种新的能力:抽象。什么是抽象呢?只关注关心的内容,忽略不关心的内容。假设我们要开发一个跑步的竞速游戏,怎么来定义一个跑步的人呢?一个人有多种属性,有名字,有身高,有银行卡金额,等等,但我们仅仅关注他怎么跑,所以通过接口表达的抽象类似:
class Runner {
public:
virtual void run() = 0;
};这就够了,明天游戏要修改为龟兔赛跑,那么可以从这个接口继承实现不同动物的run过程,上层的比赛机制完全不需要知道到底是人在跑,还是乌龟在跑,这就是抽象的能力。这种能力使软件的调用过程有了中间的接口层作为契约,调用方不会直接看到实现细节,修改只要遵守接口契约,就不会影响到调用方,进而到达解耦的目的。
Golang的鸭子类型更进一步凸显了上述观点:只要一个事物走路像鸭子,叫声像鸭子,那么就认为它是鸭子。具体鸭子是用来炖汤,还是放生到湖里游泳,动物保护者可能会关心,软件显然是不应该关心的。程序的执行过程不再是面向过程的函数调用金子塔,而转换为类之间的交互过程。对问题的建模方式不再是拆分函数,定义数据。而是通过类来抽象表达实际问题中的概念和模型,用代码模拟这些概念和模型的交互最终实现软件目的,即以更贴近现实的角度来描述和解决问题。
说了这么多抽象的话题,那怎么才算是面向对象呢?写C这类本身不支持面向对象能力的语言就是面向过程?写Java这类纯面向对象的编程语言就是面向对象?
非也,面向对象更多的是一种问题思考和解决方式,和语言的关系不大。刚才也提到,面向对象的本质是将数据和行为绑定在一起,添加指针的间接函数调用,现代的C开源库(Nginx, Linux kernal)中能见到很多结构体中带函数指针的例子,其实际上就是面向对象的编程思想。而我也见过很多Java项目中定义大量全局的数据结构,分散在各地的代码直接拿到数据的实例进行访问和修改,臃肿的上帝类参与到整个业务流程的方方面面,这也很难算的上是面向对象。
那怎么样才能有效面向对象编程呢?

SOLID原则
好在先贤们已经总结了很多经验,这里介绍下伟大的SOLID的原则。SOLID原则最早由Uncle Bob在2000年初提出,所谓SOLID其实是五个设计原则的首字母缩写,分别是:
SRP(Single Responsibility Principle): 单一职责原则,一个类或者模块应该只承担一种职责。
OCP(Open/Closed Principle): 开闭原则,对拓展开放,对修改关闭,通俗的讲就是通过添加新的文件新的类来实现功能迭代,而非修改旧有逻辑。
LSP(Liskov Substitution Principle): 里式替换原则,继承的子类型(subtype)必须能够替换掉它们的基类型。
ISP(Interface Segregation Principle): 接口隔离原则,不应该强迫客户程序依赖并未使用的方法。
DIP(Dependency Inversion Principle): 依赖反转原则,高层模块不应该依赖于低层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
如果你还没有听说过这些神神叨叨的内容,那么且听我细细道来。
单一职责原则
单一职责原则其实很好理解,我们在设计一个类的时候应该让其功能内聚,只负责一个事情,但难点在于职责的范围该怎么划分。举个例子:我们现在有一个矩形的类
class Rectangle {
public:
void draw();
double area();
};draw接口负责将矩形绘制到屏幕上,area负责计算矩形的面积。这样的设计有问题吗?
如果这个类被一个终端程序使用,它在使用绘制方法的同时,也可能会使用area做一些图形计算,这么设计就是合理的。如果被后端程序使用,那么一定不会用到绘制功能,这么设计就是不合理的。
职责范围的划分并没有什么绝对标准,不同的功能定位,不同的问题范围都会影响职责的划分逻辑,拆的很碎会导致很多的贫血类反而会增加复杂度,但不拆分又会导致臃肿的全能类,笔者的建议是在初期设计阶段保证大致的职责拆分就好,随着需求迭代和代码维护,团队和个人都会对业务场景和设计产生更深的理解,与其前期纠结于细致的拆分,不如把代码设计的更容易变更,这就是后续几个原则要说的内容。当然也不要完全不管不顾的开发,胡子眉毛一把抓,明显的职责拆分在前期还是必不可少的,凡是有度,不审势即宽严皆误。
开闭原则
开闭原则可以说是几个原则的总纲,在设计和写代码的过程中要力图做到不修改旧代码而拓展新功能。这么做的好处是显而易见的:
-
如果新的功能完全不修改旧的代码,那么影响范围就是可控的,测试起来也会很容易。
-
更意味着软件的架构是容易拓展的,新的开发人员不用过多梳理老的代码逻辑,只遵守固定的接口契约开发自己的新功能即可,理解成本就会很低。
那怎么才能遵守开闭原则呢?还是抽象。通过接口来表达意图,调用方不感知接口的实现,新的功能就可以通过新增派生来实现。举个例子,现在有个报表的功能,输入相同的数据生成不同格式的报表:
class IReporter{
public:
virtual void generate(InputData) = 0;
};不同的报表生成方式可以继承这个接口来实现,辅助上一个静态注册的工厂,我们就可以实现零修改的添加新报表格式:
class ReporterFactor {
private:
static std::map<std::string, IReporter*> reporter_map;
public:
static bool registe(std::string name, IReporter*);
static IReporter* getReporter(std::string name);
};新增加的类在自己的实现中主动调用工厂注册,上层具体使用什么样的报表格式,可以动态变更(比如配置文件),整个功能的拓展做到完全零修改。上述的例子是C++的玩法,因为其没有反射能力,只能主动去注册工厂。如果是Java,Golang这类支持反射的语言,新增的类甚至不用主动注册,通过动态扫描就可以自动生效。
里使替换原则
基类的实现要能完全替换父类的功能。这看起来好像是显而易见的事情,但事实并非如此。我见到过很多情况只把继承当作是代码复用方式,自己的实现和某个类类似,就继承自某个类来实现,但功能不完全等同,导致使用的时候需要添加if else判断具体的实例类型,这其实已经违背了里式替换原则。
从根本上讲,里式替换原则要求在抽象模型上派生而来的类所代表的含义是统一的,代码复用应该建立在这个基础之上,而非简单的将公共的代码提取一个基类。举个例子,我们现在有个矩形的类:
class Rectangle{
public:
virtual void SetLength(int length);
virtual int GetLength();
virtual void SetWeight(int weight);
virtual int GetWeight();
... ...
protected:
int length_;
int weight_;
};这个矩形类有两组接口,分别设置获取长和宽。我们现在要添加一个正方形,而从小我们就知道正方形是矩形的一种特殊形态,这种IS-A的关系用继承再合适不过:
class Square: public Rectangle {
public:
virtual void SetLength(int length);
virtual int GetLength();
virtual void SetWeight(int weight);
virtual int GetWeight();
... ...
};这样会有什么问题吗?新的正方形类继承了length, weight两个属性,这是一种浪费。其次,正方形类隐含了一个规则,length 和 weight会相互影响,修改其中一个另外一个就会跟着变化,这是和基类矩形不同的地方,这样的隐式规则是否对使用方有影响,可能要等到出现线上事故的时候才会发现吧。
接口隔离原则
有个类似的原则叫迪米特法原则,又叫最小知道原则,其实和接口隔离原则讲得是类似的道理。一个类使用其他接口的时候应该只需要依赖最小集,不应该依赖不需要使用的接口。我之前见过很多组件提供一个统一的接口类,将自己提供的所有能力都放到一个胖接口中,好像超市的货架一样让调用方按需使用,这就违背了接口隔离原则。
举个例子:我们有个用户操作的接口,定义如下:
class IUserOperations {
public:
virtual void viewProfile() = 0; // 查看信息
virtual void changePassword() = 0; // 修改密码
virtual void deleteUser() = 0; // 删除用户
};不同权限的用户角色来实现这组接口,deleteUser只有admin用户有权限调用,所以常规权限的类只能在deleteUser接口的实现中返回修改失败或者抛出异常。对于调用方而言,会看到所有的接口,即使永远不会删除用户。而当删除用户的接口变更时,反而会影响到不会删除用户的调用方。按照接口隔离原则,应该将这个胖接口拆分为IAdminUserOperations 和 INormalUserOperations两组接口,减少互相的干扰和影响。
依赖反转原则
之前我们讲到面向过程的编程方式,会将代码组织成一个巨大的金字塔结构的调用函数栈,上层逻辑的函数依赖底层的函数实现,这正是依赖反转要避免的事情。依赖反转原则强调高层的业务逻辑不应该依赖底层的实现细节,遵守这样的原则马上就会得到明显的收益。过往的经历中,我见到过很多项目没有办法做单元测试,常言敏捷,却还是走的瀑布式开发的路数。前期一顿低头猛写,等到上下游开始集成测试的时候再一点一点的调试排查问题。必须把数据库,消息中间件等等基础设施全都准备妥当了,才能从顶层接口处构造请求,小心翼翼地追下执行过程。依赖反转告诉我们,应该通过接口和底层实现进行解耦,这在计算机中早有先例,Linux对一个文件操作的抽象是一组接口指针:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};struct FILE console = {open, close, read, write, seek};具体指针指向的实现,是将内容写到了磁盘上,内存上,还是网络上,调用方是完全不关心的,新增加的文件类型也完全不会影响到调用方,这是经典的依赖反转原则的使用。
one more thing: 控制业务分离
在SOLID之外,还有一个原则也很值得关注,这里加餐讨论一下。
我们所有的代码可以划分到两种类型中:
1.业务逻辑:正真实现业务需求的代码逻辑,比如开发的电商业务,那么业务代码就是订单,付款之类,开发的外卖系统,那么业务代码就是订单成交,派送之类。
2.控制逻辑:并不直接实现业务,而是辅助业务逻辑的执行流程。
业务逻辑是赚钱的逻辑,设计的好增加项目收益。而控制逻辑是省钱的逻辑,写的好项目鲁棒性高,性能好,实际运行所需要的资源少。
其实在大的系统架构层面,从最早的时候没有基础设施,业务团队自己处理,到逐步下沉中间件,到后来的云原生所做的事情一直是将控制逻辑下沉,使开发人员更加聚焦业务逻辑。站在单个组件的设计层面,我们也应该有类似设计追求。核心业务逻辑不应该和控制逻辑绑定在一起,当需要进行控制逻辑重构的时候,不影响业务逻辑,方能控制修改的测试范围。
举个线程的例子,Java为我们提供了一个简单的线程封装:Thread, 只要一个类继承 Thread 并重写 run 方法,就可以具备线程执行能力,所以常见到这样的实现,比如要开发一个订单处理逻辑,可以多线程阻塞接收订单处理:
public class OrderProcessor extends Thread {
public void order_handle() {
// 阻塞接收处理逻辑
}
public void run() {
order_handle();
}
}这里将线程控制逻辑和业务逻辑绑定在了一起,当我们进行控制逻辑修改,比如要修改线程间的消息传递机制,那么这个类就需要一起修改。如果我们要添加一个新的业务流程,比如订单撤销处理,在原有得设计中,需要再新建一个CancelOrderProcessor的类继承Thread进行新的流程处理。
控制逻辑和业务逻辑不分离导致两者的修改相互影响,引入不必要的变化,限制了架构的灵活性。这个例子中我们可以将业务流程抽象一个处理过程:
public interface Bussiness {
void handle();
}不同的业务处理流程通过继承这个接口来实现自己的处理过程,在线程间投递的事件不再是不同的业务处理输入,而是这个Bussiness接口,线程逻辑只需要调用 handle()进行处理,完全不感知任何业务处理逻辑,业务处理逻辑也完全不关心到底是在哪个线程执行,是共享线程池还是多个线程池,实现控制逻辑和业务逻辑的完全解耦。
上述的这些原则中,SRP和ISP关注职责划分,OCP和DIP强调抽象解耦,LSP则是继承关系的约束。讲清楚了这些原则,大概就可以回答刚开始的问题,怎么样有效使用OOP。
有同学可能觉得还是有些玄,纵然有了原则指导,又应该如何实践呢?这就轮到设计模式登场了。
设计模式
关于设计模式的资料已经汗牛充栋,我在这里不再将所有的设计模式像设计原则一样一一讲解,只是从宏观的角度上大体概括一下。
设计模式都有哪些呢?这里有一个口诀:
单(单例)抽(抽象工厂)工(工厂)元(元型)建(建造者)。
责(责任链)令(命令行)策(策略)访(访问者)迭(迭代器)。
中(中介者)观(观察者)解(解释器),备(备忘录)模(模版方法)态(状态机)。
适(适配器)装(装饰器)乔(乔接)组(组合)享(享元)代(代理)外(外观)。
每种设计模又都可以归类到不同的软件设计场景上:
类的创建过程:单 抽 工 元 建
程序的行为:责 令 策 访 迭,中 观 解,备 模 态
程序的结构:适 装 乔 组 享 代 外
23种设计模式都在其间,此组口诀是我多年的修炼成果,轻易不可外传,每天早上默背五遍,自可耳目聪慧,写代码思如泉涌。少年,我看你骨骼轻奇…
现在一提起软件设计,不说几个设计模式好像都有些害臊,那到底什么是设计模式呢?个人感觉可以把其当作是面向对象编程特定场景下的一些最佳实践。每种设计模式都是对不同场景的问题进行抽象。简单聊几个模式:
工厂是对同类型接口实例创建过程的抽象,使依赖接口的调用方感知不到具体的类型实现。
抽象工厂是对工厂的再一次抽象,很多文章中说抽象工厂是对产品簇创建的抽象,搞得人一头雾水。其本质是:抽象工厂创建工厂,然后工厂再创建具体的实例。
建造者是对复杂建造过程的封装,当一个类实例创建过程有复杂逻辑的时候,可以将这些逻辑显式统一放到建造者中维护。
责任链是对统一执行策略的排布抽象,当有数据需要进过一系列策略的处理时,可以将这些策略通过责任量链模式组合使用,显式管理。
策略模式是对算法的抽象,当一个算法可以有多种实现的时候,可以将算法提炼接口,通过策略模式动态的调配具体的实现。
迭代器模式是对迭代过程的抽象,使主动迭代的调用方感知不到被迭代的具体实现。
观察者模式是对调用关系的抽象,使调用方不再关注被调用方,将接口调用过程抽象为事件通知过程。
… …
当你遇到类似场景的时候,优先要考虑能否使用设计模式,尤其是当你觉得自己还不能创造新设计模式的时候,更要谨慎的考虑既然场景如此相似,你的方式比之设计模式有何优势?当然,上述对比的前提是你已经知道了设计模式以及对应的使用场景。新入行的朋友可能无法理解设计模式的意图,看书也味同嚼蜡,不得要领,这也是正常现象。没有一定的代码积累很难顺利的理解设计模式,这也是设计模式的难点,如果人人都会的话,又怎么会显得高端呢?我的建议是像背课文一样,即使不太明白,也要背下来(口诀!口诀!口诀!), 平时的时候多看多写,看到设计模式的使用场景,多琢磨。正所谓书读百遍,其意自现,终会有醍醐灌顶的时候。
行文至此,已经洋洋洒洒了几千字。我们讨论了为什么需要面向对象,又讨论了面向对象的使用原则,还讨论了面向对象的最佳实践。然而,纸上得来终觉浅,绝知此事要躬行。很多设计规则只通过看书看文章很难理解透彻,只有知道了为什么不好,才能知道这些模式为什么好。
用耳去听,用心去想,愿代码的智慧与你同在。